What is BlenderGym?
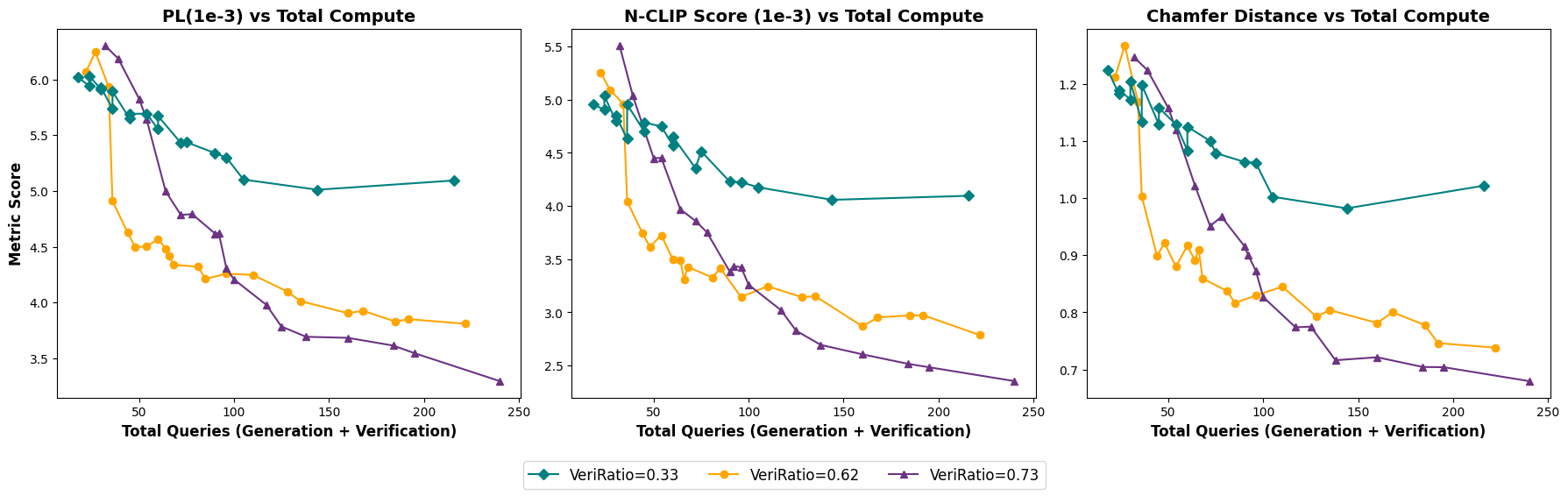
BlenderGym consists of 245 hand-crafted Blender scenes across 5 key graphics editing tasks: procedural geometry editing, lighting adjustments, procedural material design, blend shape manipulation, and object placement.
1Procedural Geometry
Handling variations in spatial and geometrical attributes like shape, scale, and spatial distribution.

2Lighting Adjustments
Manipulating the color, intensity, location, and orientation of the light sources.

3Procedural Material
Editing color, texture, displacement, and patterns of a surface material.

4Blend Shape manipulation
Adjusting blend shapes, continuous variables that control some features of an object, such as facial expressions.

5Object Placement
Perceiving and adjusting the location of the objects in the scene.

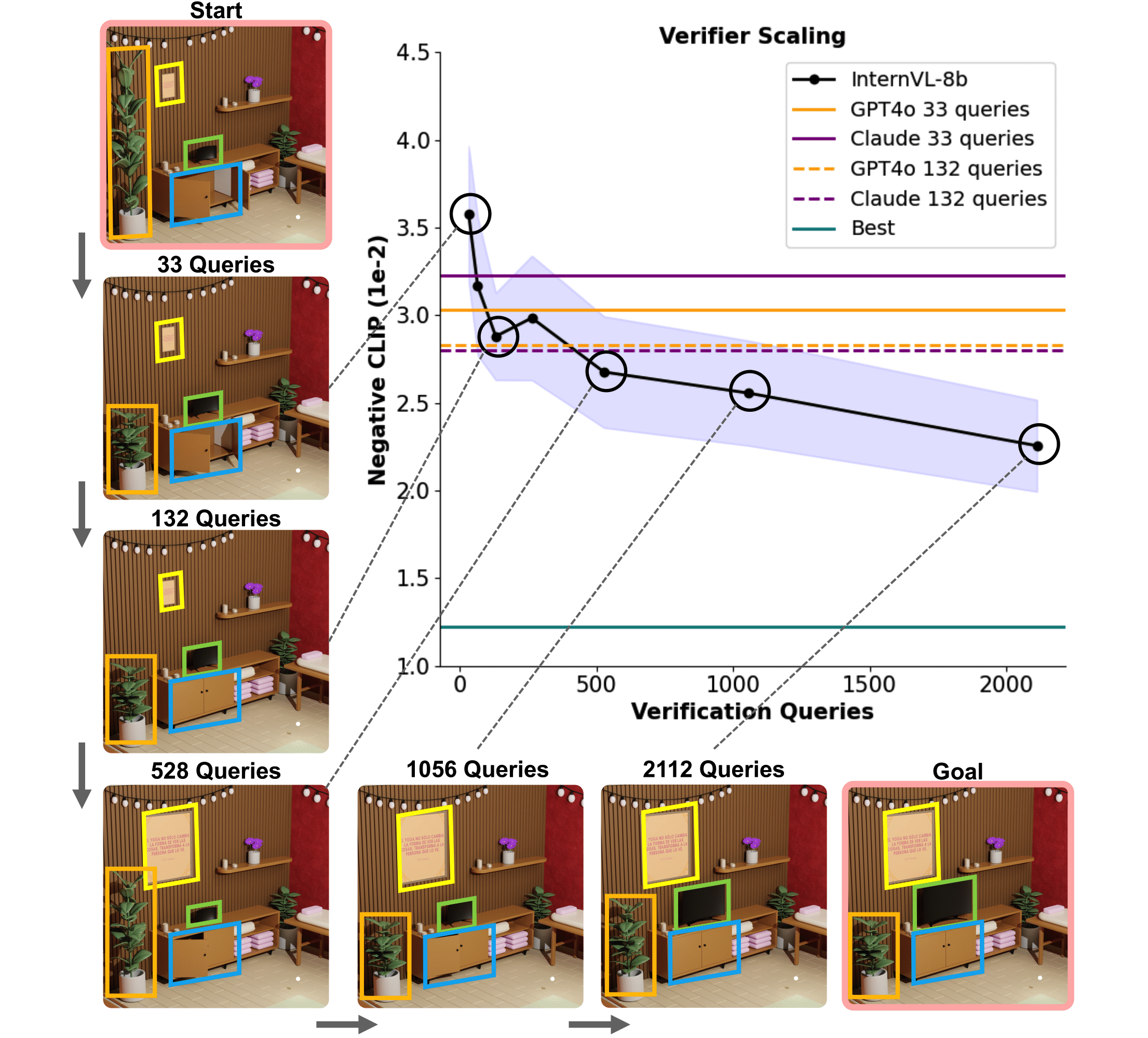
Each instance in BlenderGym presents a reconstruction task from a start scene to a goal scene. Each start-goal instance includes:
- A base Blender file of the scene setup
- A pair of Python scripts that generate the start and goal scene
- Rendered images for both scenes
- Language description of the differences between the two scenes